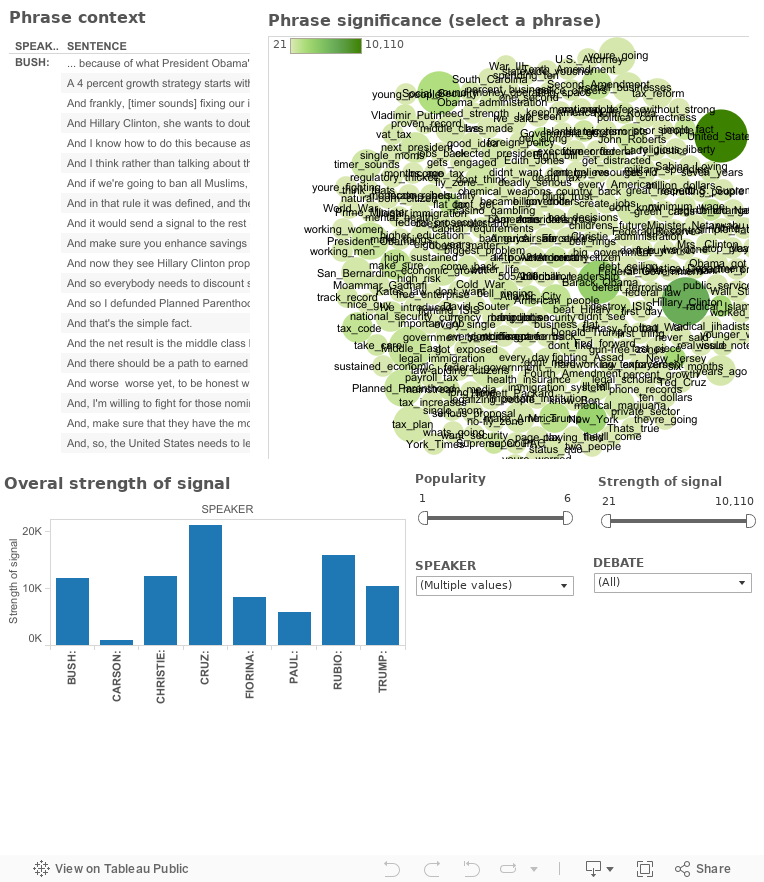
Objectivity analysis of Rubio's Iowa speech
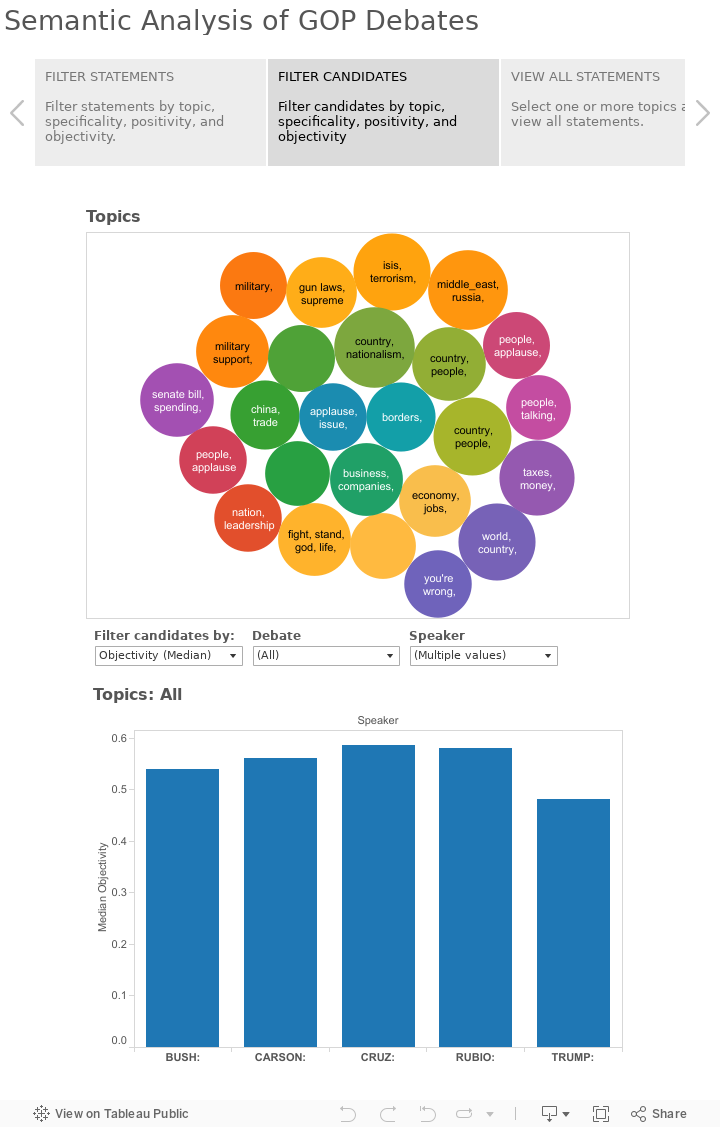
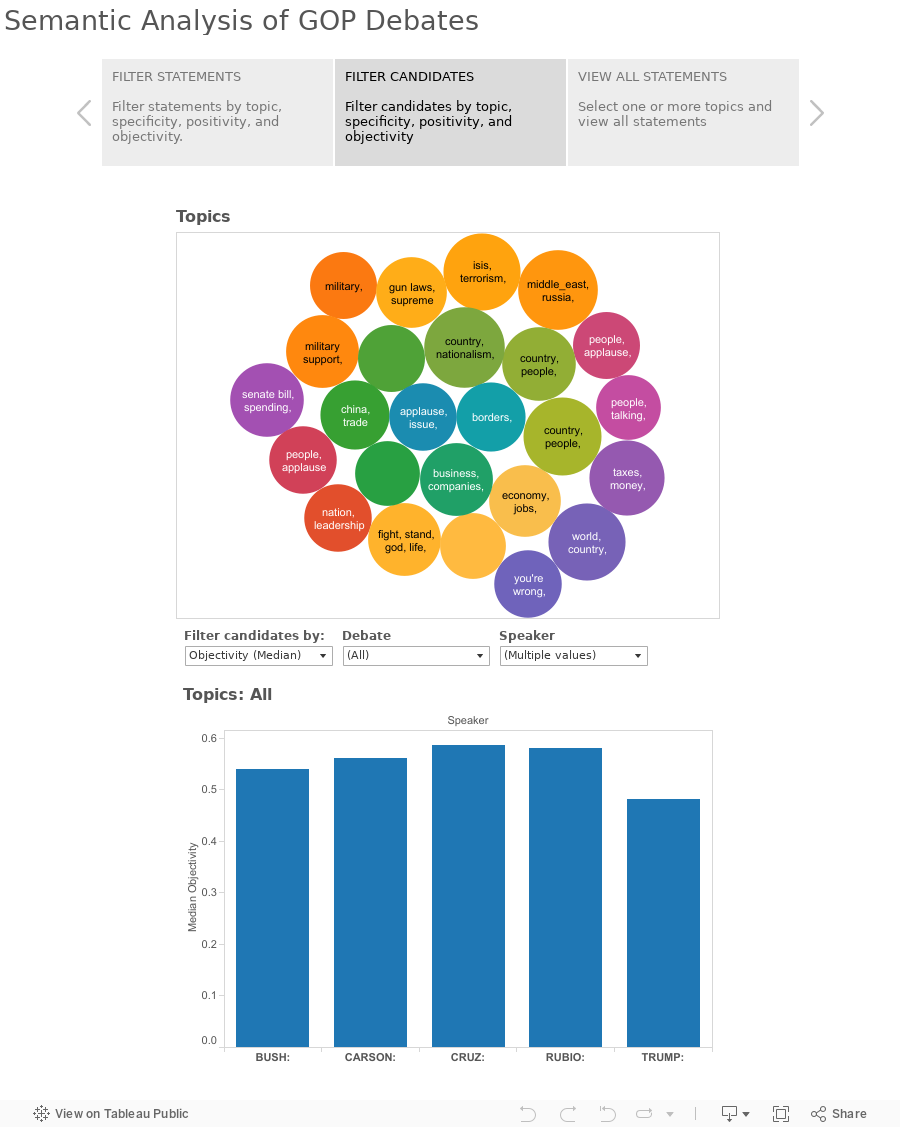
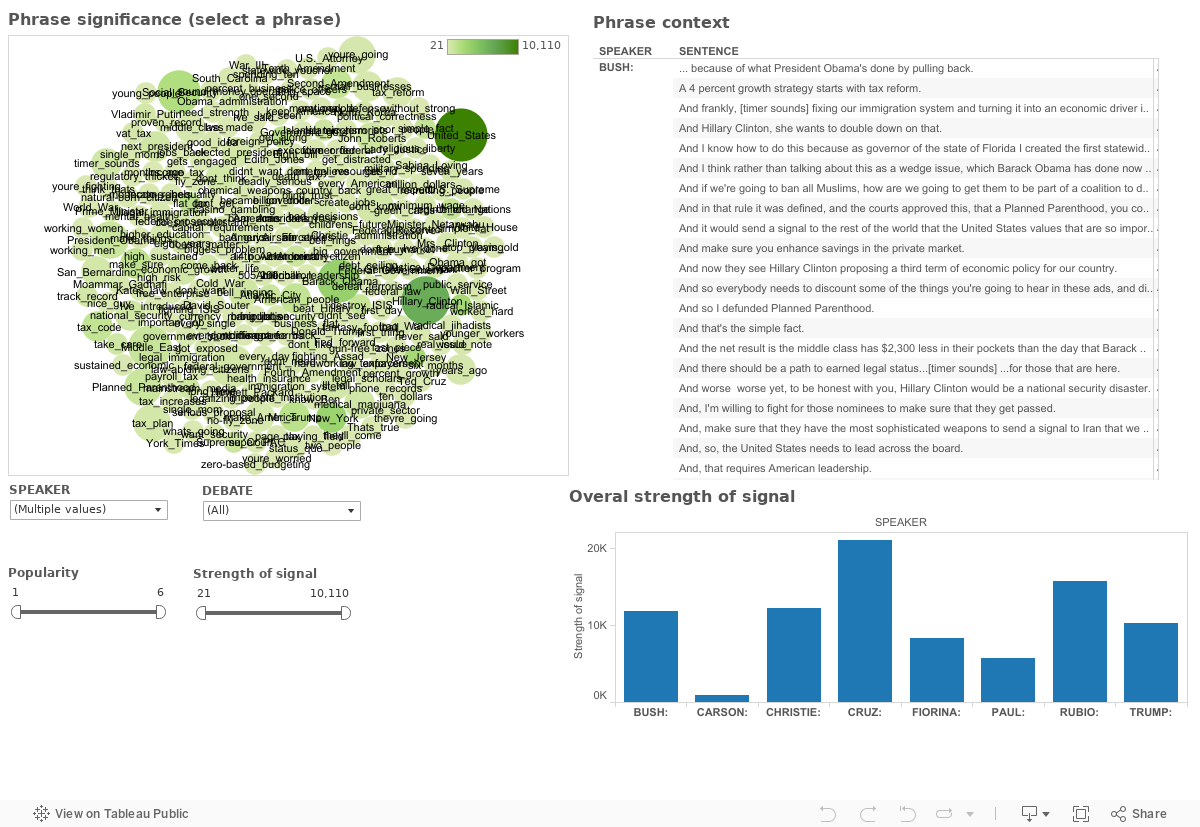
By special request, here is a topical breakdown of Rubio's Feb 1, 2016 "Iowa" speech, after his surprising results at the Iowa caucuses, using the topic model trained on GOP Debate speeches.
Given the small sample size, some of the topics are a bit out of whack but I cleaned it up as much as I could and tried to focus on longer statements with strong topic representation. Below are some of the more significant ones.
I also used a simple, off-the-shelf sentiment analyzer which measures the objectivity of a sentence on a purely lexical basis -- e.g. "I think" is less objective than, "I know." It's not purely weighted by verb mood like in my example, but it's not super sophisticated either.
Clearly, objectivity is not the same as substance -- it's easy to make long, sweeping objective statements that have low topical substance. Perhaps there is a way I can create an overall "substance" index weighted by lexical objectivity and some metric of inner-topic coverage to provide a more semantically qualitative measure of the statement. Indeed, at first glance, "valueless" statements appear to have many more uniformly weak topics, rather than a few strong signals -- sort of a topic cohesion measure. Food for thought....
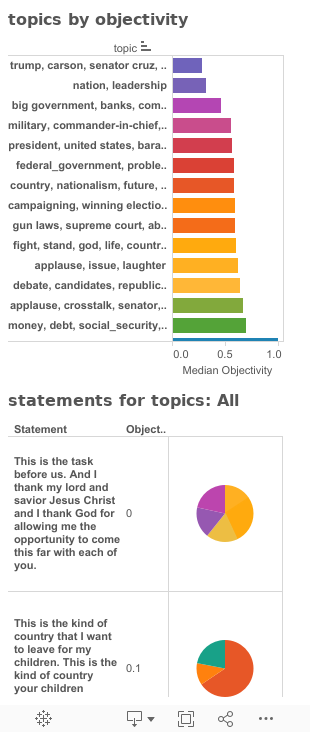
Anyway, here are the most significant phrases in Rubio's Iowa speech, by overall lexical objectivity. The top bar chart shows the overall topic, and it's average (median) objectivity; the table below shows the actual statements, and their topic distributions in the form of a pie chart. The color of each slice represents the topic (you can hover over for the value), and the size of the slice is proportional to it's objectivity.
As you can see, for example, the first statement in the table "I thank my Lord and Savior Jesus Christ...", etc. you will see that the objectivity score is zero. When you scroll to the bottom of the table, the statement "When my parents first arrived here in this country...", etc. you will see it scores as "purely" objective, with a score of 1.
If you scroll the bar chart, you can see which topics are generally more or less objective than others. There are some interesting things in there.
It's hard to make this work well on a mobile browser, but I tried.